This post was co-written with Lucas Desard, Tom Lauwers, and Sam Landuydt from DPG Media.
DPG Media is a leading media company in Benelux operating multiple online platforms and TV channels. DPG Media’s VTM GO platform alone offers over 500 days of non-stop content.
With a growing library of long-form video content, DPG Media recognizes the importance of efficiently managing and enhancing video metadata such as actor information, genre, summary of episodes, the mood of the video, and more. Having descriptive metadata is key to providing accurate TV guide descriptions, improving content recommendations, and enhancing the consumer’s ability to explore content that aligns with their interests and current mood.
This post shows how DPG Media introduced AI-powered processes using Amazon Bedrock and Amazon Transcribe into its video publication pipelines in just 4 weeks, as an evolution towards more automated annotation systems.
The challenge: Extracting and generating metadata at scale
DPG Media receives video productions accompanied by a wide range of marketing materials such as visual media and brief descriptions. These materials often lack standardization and vary in quality. As a result, DPG Media Producers have to run a screening process to consume and understand the content sufficiently to generate the missing metadata, such as brief summaries. For some content, additional screening is performed to generate subtitles and captions.
As DPG Media grows, they need a more scalable way of capturing metadata that enhances the consumer experience on online video services and aids in understanding key content characteristics.
The following were some initial challenges in automation:
- Language diversity – The services host both Dutch and English shows. Some local shows feature Flemish dialects, which can be difficult for some large language models (LLMs) to understand.
- Variability in content volume – They offer a range of content volume, from single-episode films to multi-season series.
- Release frequency – New shows, episodes, and movies are released daily.
- Data aggregation – Metadata needs to be available at the top-level asset (program or movie) and must be reliably aggregated across different seasons.
Solution overview
To address the challenges of automation, DPG Media decided to implement a combination of AI techniques and existing metadata to generate new, accurate content and category descriptions, mood, and context.
The project focused solely on audio processing due to its cost-efficiency and faster processing time. Video data analysis with AI wasn’t required for generating detailed, accurate, and high-quality metadata.
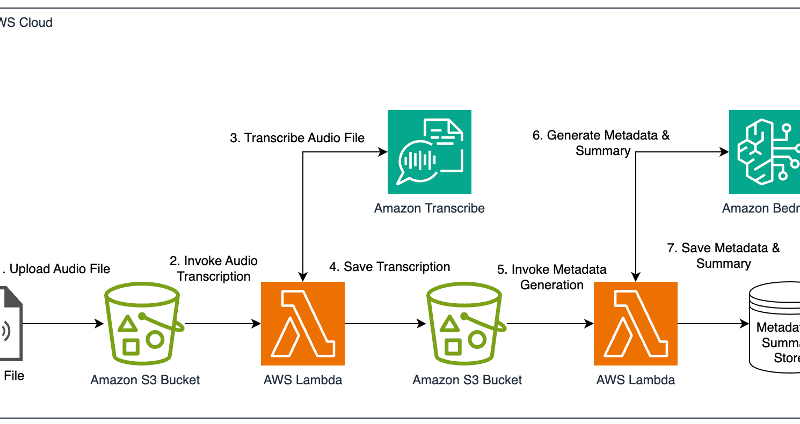
The following diagram shows the metadata generation pipeline from audio transcription to detailed metadata.
The general architecture of the metadata pipeline consists of two primary steps:
- Generate transcriptions of audio tracks: use speech recognition models to generate accurate transcripts of the audio content.
- Generate metadata: use LLMs to extract and generate detailed metadata from the transcriptions.
In the following sections, we discuss the components of the pipeline in more detail.
Step 1. Generate transcriptions of audio tracks
To generate the necessary audio transcripts for metadata extraction, the DPG Media team evaluated two different transcription strategies: Whisper-v3-large, which requires at least 10 GB of vRAM and high operational processing, and Amazon Transcribe, a managed service with the added benefit of automatic model updates from AWS over time and speaker diarization. The evaluation focused on two key factors: price-performance and transcription quality.
To evaluate the transcription accuracy quality, the team compared the results against ground truth subtitles on a large test set, using the following metrics:
- Word error rate (WER) – This metric measures the percentage of words that are incorrectly transcribed compared to the ground truth. A lower WER indicates a more accurate transcription.
- Match error rate (MER) – MER assesses the proportion of correct words that were accurately matched in the transcription. A lower MER signifies better accuracy.
- Word information lost (WIL) – This metric quantifies the amount of information lost due to transcription errors. A lower WIL suggests fewer errors and better retention of the original content.
- Word information preserved (WIP) – WIP is the opposite of WIL, indicating the amount of information correctly captured. A higher WIP score reflects more accurate transcription.
- Hits – This metric counts the number of correctly transcribed words, giving a straightforward measure of accuracy.
Both experiments transcribing audio yielded high-quality results without the need to incorporate video or further speaker diarization. For further insights into speaker diarization in other use cases, see Streamline diarization using AI as an assistive technology: ZOO Digital’s story.
Considering the varying development and maintenance efforts required by different alternatives, DPG Media chose Amazon Transcribe for the transcription component of their system. This managed service offered convenience, allowing them to concentrate their resources on obtaining comprehensive and highly accurate data from their assets, with the goal of achieving 100% qualitative precision.
Step 2. Generate metadata
Now that DPG Media has the transcription of the audio files, they use LLMs through Amazon Bedrock to generate the various categories of metadata (summaries, genre, mood, key events, and so on). Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Through Amazon Bedrock, DPG Media selected the Anthropic Claude 3 Sonnet model based on internal testing, and the Hugging Face LMSYS Chatbot Arena Leaderboard for its reasoning and Dutch language performance. Working closely with end-consumers, the DPG Media team tuned the prompts to make sure the generated metadata matched the expected format and style.
After the team had generated metadata at the individual video level, the next step was to aggregate this metadata across an entire series of episodes. This was a critical requirement, because content recommendations on a streaming service are typically made at the series or movie level, rather than the episode level.
To generate summaries and metadata at the series level, the DPG Media team reused the previously generated video-level metadata. They fed the summaries in an ordered and structured manner, along with a specifically tailored system prompt, back through Amazon Bedrock to Anthropic Claude 3 Sonnet.
Using the summaries instead of the full transcriptions of the episodes was sufficient for high-quality aggregated data and was more cost-efficient, because many of DPG Media’s series have extended runs.
The solution also stores the direct association between each type of metadata and its corresponding system prompt, making it straightforward to tune, remove, or add prompts as needed—similar to the adjustments made during the development process. This flexibility allows them to tailor the metadata generation to evolving business requirements.
To evaluate the metadata quality, the team used reference-free LLM metrics, inspired by LangSmith. This approach used a secondary LLM to evaluate the outputs based on tailored metrics such as if the summary is simple to understand, if it contains all important events from the transcription, and if there are any hallucinations in the generated summary. The secondary LLM is used to evaluate the summaries on a large scale.
Results and lessons learned
The implementation of the AI-powered metadata pipeline has been a transformative journey for DPG Media. Their approach saves days of work generating metadata for a TV series.
DPG Media chose Amazon Transcribe for its ease of transcription and low maintenance, with the added benefit of incremental improvements by AWS over the years. For metadata generation, DPG Media chose Anthropic Claude 3 Sonnet on Amazon Bedrock, instead of building direct integrations to various model providers. The flexibility to experiment with multiple models was appreciated, and there are plans to try out Anthropic Claude Opus when it becomes available in their desired AWS Region.
DPG Media decided to strike a balance between AI and human expertise by having the results generated by the pipeline validated by humans. This approach was chosen because the results would be exposed to end-customers, and AI systems can sometimes make mistakes. The goal was not to replace people but to enhance their capabilities through a combination of human curation and automation.
Transforming the video viewing experience is not merely about adding more descriptions, it’s about creating a richer, more engaging user experience. By implementing AI-driven processes, DPG Media aims to offer better-recommended content to users, foster a deeper understanding of its content library, and progress towards more automated and efficient annotation systems. This evolution promises not only to streamline operations but also to align content delivery with modern consumption habits and technological advancements.
Conclusion
In this post, we shared how DPG Media introduced AI-powered processes using Amazon Bedrock into its video publication pipelines. This solution can help accelerate audio metadata extraction, create a more engaging user experience, and save time.
We encourage you to learn more about how to gain a competitive advantage with powerful generative AI applications by visiting Amazon Bedrock and trying this solution out on a dataset relevant to your business.
About the Authors
 Lucas Desard is GenAI Engineer at DPG Media. He helps DPG Media integrate generative AI efficiently and meaningfully into various company processes.
Lucas Desard is GenAI Engineer at DPG Media. He helps DPG Media integrate generative AI efficiently and meaningfully into various company processes.
 Tom Lauwers is a machine learning engineer on the video personalization team for DPG Media. He builds and architects the recommendation systems for DPG Media’s long-form video platforms, supporting brands like VTM GO, Streamz, and RTL play.
Tom Lauwers is a machine learning engineer on the video personalization team for DPG Media. He builds and architects the recommendation systems for DPG Media’s long-form video platforms, supporting brands like VTM GO, Streamz, and RTL play.
 Sam Landuydt is the Area Manager Recommendation & Search at DPG Media. As the manager of the team, he guides ML and software engineers in building recommendation systems and generative AI solutions for the company.
Sam Landuydt is the Area Manager Recommendation & Search at DPG Media. As the manager of the team, he guides ML and software engineers in building recommendation systems and generative AI solutions for the company.
 Irina Radu is a Prototyping Engagement Manager, part of AWS EMEA Prototyping and Cloud Engineering. She helps customers get the most out of the latest tech, innovate faster, and think bigger.
Irina Radu is a Prototyping Engagement Manager, part of AWS EMEA Prototyping and Cloud Engineering. She helps customers get the most out of the latest tech, innovate faster, and think bigger.
 Fernanda Machado, AWS Prototyping Architect, helps customers bring ideas to life and use the latest best practices for modern applications.
Fernanda Machado, AWS Prototyping Architect, helps customers bring ideas to life and use the latest best practices for modern applications.
 Andrew Shved, Senior AWS Prototyping Architect, helps customers build business solutions that use innovations in modern applications, big data, and AI.
Andrew Shved, Senior AWS Prototyping Architect, helps customers build business solutions that use innovations in modern applications, big data, and AI.
Source link
lol