Large enterprises are building strategies to harness the power of generative AI across their organizations. However, scaling up generative AI and making adoption easier for different lines of businesses (LOBs) comes with challenges around making sure data privacy and security, legal, compliance, and operational complexities are governed on an organizational level. In this post, we discuss how to address these challenges holistically.
Managing bias, intellectual property, prompt safety, and data integrity are critical considerations when deploying generative AI solutions at scale. Because this is an emerging area, best practices, practical guidance, and design patterns are difficult to find in an easily consumable basis. In this post, we share AWS guidance that we have learned and developed as part of real-world projects into practical guides oriented towards the AWS Well-Architected Framework, which is used to build production infrastructure and applications on AWS. We focus on the operational excellence pillar in this post.
Amazon Bedrock plays a pivotal role in this endeavor. It’s a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like Anthropic, Cohere, Meta, Mistral AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. You can securely integrate and deploy generative AI capabilities into your applications using services such as AWS Lambda, enabling seamless data management, monitoring, and compliance (for more details, see Monitoring and observability). This integration makes sure enterprises can take advantage of the full power of generative AI while adhering to best practices in operational excellence.
With Amazon Bedrock, enterprises can achieve the following:
- Scalability – Scale generative AI applications across different LOBs without compromising performance
- Security and compliance – Enforce data privacy, security, and compliance with industry standards and regulations
- Operational efficiency – Streamline operations with built-in tools for monitoring, logging, and automation, aligned with the AWS Well-Architected Framework
- Innovation – Access cutting-edge AI models and continually improve them with real-time data and feedback
This approach enables enterprises to deploy generative AI at scale while maintaining operational excellence, ultimately driving innovation and efficiency across their organizations.
What’s different about operating generative AI workloads and solutions?
The operational excellence pillar of the Well-Architected Framework is mainly focused on supporting the development and running of workloads effectively, gaining insight into their operations, and continuously improving supporting processes and procedures to deliver business value. However, if we were to apply a generative AI lens, we would need to address the intricate challenges and opportunities arising from its innovative nature, encompassing the following aspects:
- Complexity can be unpredictable due to the ability of large language models (LLMs) to generate new content
- Potential intellectual property infringement is a concern due to the lack of transparency in the model training data
- Low accuracy in generative AI can create incorrect or controversial content
- Resource utilization requires a specific operating model to meet the substantial computational resources required for training and prompt and token sizes
- Continuous learning necessitates additional data annotation and curation strategies
- Compliance is also a rapidly evolving area, where data governance becomes more nuanced and complex, and poses challenges
- Integration with legacy systems requires careful considerations of compatibility, data flow between systems, and potential performance impacts.
Any generative AI lens therefore needs to combine the following elements, each with varying levels of prescription and enforcement, to address these challenges and provide the basis for responsible AI usage:
- Policy – The system of principles to guide decisions
- Guardrails – The rules that create boundaries to keep you within the policy
- Mechanisms – The process and tools
AWS has advanced responsible AI by introducing Amazon Bedrock Guardrails as a protection to prevent harmful responses from the LLMs, providing an additional layer of safeguards regardless of the underlying FM. However, a more holistic organizational approach is crucial because generative AI practitioners, data scientists, or developers can potentially use a wide range of technologies, models, and datasets to circumvent the established controls.
As cloud adoption has matured for more traditional IT workloads and applications, the need to help developers select the right cloud solution that minimizes corporate risk and simplifies the developer experience has emerged. This is often referred to as platform engineering and can be neatly summarized by the mantra “You (the developer) build and test, and we (the platform engineering team) do all the rest!”
This approach, when applied to generative AI solutions, means that a specific AI or machine learning (ML) platform configuration can be used to holistically address the operational excellence challenges across the enterprise, allowing the developers of the generative AI solution to focus on business value. This is illustrated in the following diagram.
Where to start?
We start this post by reviewing the foundational operational elements a generative AI platform team needs to initially focus on as they transition generative solutions from a proof of concept or prototype phase to a production-ready solution.
Specifically, we cover how you can safely develop, deploy, and monitor models, mitigating operational and compliance risks, thereby reducing the friction in adopting AI at scale and for production use. We focus on the following four design principles:
- Establish control through promoting transparency of model details, setting up guardrails or safeguards, and providing visibility into costs, metrics, logs, and traces
- Automate model fine-tuning, training, validation, and deployment using large language model operations (LLMOps) or foundation model operations (FMOps)
- Manage data through standard methods for ingestion, governance, and indexing
- Provide managed infrastructure patterns and blueprints for models, prompt catalogs, APIs, and access control guidelines
In the following sections, we explain this using an architecture diagram while diving into the best practices of the control pillar.
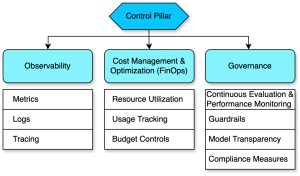
Provide control through transparency of models, guardrails, and costs using metrics, logs, and traces
The control pillar of the generative AI framework focuses on observability, cost management, and governance, making sure enterprises can deploy and operate their generative AI solutions securely and efficiently. The following diagram illustrates the key components of this pillar:

Observability
Setting up observability measures lays the foundations for the other two components, namely FinOps and Governance. Observability is crucial for monitoring the performance, reliability, and cost-efficiency of generative AI solutions. By using AWS services such as Amazon CloudWatch, AWS CloudTrail, and Amazon OpenSearch Service, enterprises can gain visibility into model metrics, usage patterns, and potential issues, enabling proactive management and optimization.
Amazon Bedrock is compatible with robust observability features to monitor and manage ML models and applications. Key metrics integrated with CloudWatch include invocation counts, latency, client and server errors, throttles, input and output token counts, and more (for more details, see Monitor Amazon Bedrock with Amazon CloudWatch). You can also use Amazon EventBridge to monitor events related to Amazon Bedrock. This allows you to create rules that invoke specific actions when certain events occur, enhancing the automation and responsiveness of your observability setup (for more details, see Monitor Amazon Bedrock). CloudTrail can log all API calls made to Amazon Bedrock by a user, role, or AWS service in an AWS environment. This is particularly useful for tracking access to sensitive resources such as personally identifiable information (PII), model updates, and other critical activities, enabling enterprises to maintain a robust audit trail and compliance. To learn more, see Log Amazon Bedrock API calls using AWS CloudTrail.
Amazon Bedrock supports the metrics and telemetry needed for implementing an observability maturity model for LLMs, which includes the following:
- Capturing and analyzing LLM-specific metrics such as model performance, prompt properties, and cost metrics through CloudWatch
- Implementing alerts and incident management tailored to LLM-related issues
- Providing security compliance and robust monitoring mechanisms, because Amazon Bedrock is in scope for common compliance standards and offers automated abuse detection mechanisms
- Using CloudWatch and CloudTrail for anomaly detection, usage and costs forecasting, optimizing performance, and resource utilization
- Using AWS forecasting services for better resource planning and cost management
CloudWatch provides a unified monitoring and observability service that collects logs, metrics, and events from various AWS services and on-premises sources. This allows enterprises to track key performance indicators (KPIs) for their generative AI models, such as I/O volumes, latency, and error rates. You can use CloudWatch dashboards to create custom visualizations and alerts, so teams are quickly notified of any anomalies or performance degradation.
For more advanced observability requirements, enterprises can use OpenSearch Service, a fully managed service for deploying, operating, and scaling OpenSearch and Kibana. Opensearch Dashboards provides powerful search and analytical capabilities, allowing teams to dive deeper into generative AI model behavior, user interactions, and system-wide metrics.
Additionally, you can enable model invocation logging to collect invocation logs, full request response data, and metadata for all Amazon Bedrock model API invocations in your AWS account. Before you can enable invocation logging, you need to set up an Amazon Simple Storage Service (Amazon S3) or CloudWatch Logs destination. You can enable invocation logging through either the AWS Management Console or the API. By default, logging is disabled.
Cost management and optimization (FinOps)
Generative AI solutions can quickly scale and consume significant cloud resources, and a robust FinOps practice is essential. With services like AWS Cost Explorer and AWS Budgets, enterprises can track their usage and optimize their generative AI spending, achieving cost-effective deployment and scaling.
Cost Explorer provides detailed cost analysis and forecasting capabilities, enabling you to understand your tenant-related expenditures, identify cost drivers, and plan for future growth. Teams can create custom cost allocation reports, set custom budgets using AWS budgets and alerts, and explore cost trends over time.
Analyzing the cost and performance of generative AI models is crucial for making informed decisions about model deployment and optimization. EventBridge, CloudTrail, and CloudWatch provide the necessary tools to track and analyze these metrics, helping enterprises make data-driven decisions. With this information, you can identify optimization opportunities, such as scaling down under-utilized resources.
With EventBridge, you can configure Amazon Bedrock to respond automatically to status change events in Amazon Bedrock. This enables you to handle API rate limit issues, API updates, and reduction in additional compute resources. For more details, see Monitor Amazon Bedrock events in Amazon EventBridge.
As discussed in previous section, CloudWatch can monitor Amazon Bedrock to collect raw data and process it into readable, near real-time cost metrics. You can graph the metrics using the CloudWatch console. You can also set alarms that watch for certain thresholds, and send notifications or take actions when values exceed those thresholds. For more information, see Monitor Amazon Bedrock with Amazon CloudWatch.
Governance
Implementation of robust governance measures, including continuous evaluation and multi-layered guardrails, is fundamental for the responsible and effective deployment of generative AI solutions in enterprise environments. Let’s look at them one by one:
- Performance monitoring and evaluation – Continuously evaluating the performance, safety, and compliance of generative AI models is critical. You can achieve this in several ways:
- Enterprises can use AWS services like Amazon SageMaker Model Monitor and Amazon Bedrock Guardrails, or Amazon Comprehend to monitor model behavior, detect drifts, and make sure generative AI solutions are performing as expected (or better) and adhering to organizational policies.
- You can deploy open-source evaluation metrics like RAGAS as custom metrics to make sure LLM responses are grounded, mitigate bias, and prevent hallucinations.
- Model evaluation jobs allow you to compare model outputs and choose the best-suited model for your use case. The job could be automated based on a ground truth, or you could use humans to bring in expertise on the matter. You can also use FMs from Amazon Bedrock to evaluate your applications. To learn more about this approach, refer to Evaluate the reliability of Retrieval Augmented Generation applications using Amazon Bedrock.
- Guardrails – Generative AI solutions should include robust, multi-level guardrails to enforce responsible AI and oversight:
- First, you need guardrails around the LLM model to mitigate risks around bias and safeguard the application with responsible AI policies. This can be done through Amazon Bedrock Guardrails to set up custom guardrails around a model (FM or fine-tuned) for configuring denied topics, content filters, and blocked messaging.
- The second level is to set guardrails around the framework for each use case. This includes implementing access controls, data governance policies, and proactive monitoring and alerting to make sure sensitive information is properly secured and monitored. For example, you can use AWS data analytics services such as Amazon Redshift for data warehousing, AWS Glue for data integration, and Amazon QuickSight for business intelligence (BI).
- Compliance measures – Enterprises need to set up a robust compliance framework to meet regulatory requirements and industry standards such as GDPR, CCPA, or industry-specific standards. This helps make sure generative AI solutions remain secure, compliant, and efficient in handling sensitive information across different use cases. This approach minimizes the risk of data breaches or unauthorized data access, thereby protecting the integrity and confidentiality of critical data assets. Enterprises can take the following organization-level actions to create a comprehensive governance structure:
- Establish a clear incident response plan for addressing compliance breaches or AI system malfunctions.
- Conduct periodic compliance assessments and third-party audits to identify and address potential risks or violations.
- Provide ongoing training to employees on compliance requirements and best practices in AI governance.
- Model transparency – Although achieving full transparency in generative AI models remains challenging, organizations can take several steps to enhance model transparency and explainability:
- Provide model cards on the model’s intended use, performance, capabilities, and potential biases.
- Ask the model to self-explain, meaning provide explanations for their own decisions. This can also be set in a complex system—for example, agents could perform multi-step planning and improve through self-explanation.
Automate model lifecycle management with LLMOps or FMOps
Implementing LLMOps is crucial for efficiently managing the lifecycle of generative AI models at scale. To grasp the concept of LLMOps, a subset of FMOps, and the key differentiators compared to MLOps, see FMOps/LLMOps: Operationalize generative AI and differences with MLOps. In that post, you can learn more about the developmental lifecycle of a generative AI application and the additional skills, processes, and technologies needed to operationalize generative AI applications.
Manage data through standard methods of data ingestion and use
Enriching LLMs with new data is imperative for LLMs to provide more contextual answers without the need for extensive fine-tuning or the overhead of building a specific corporate LLM. Managing data ingestion, extraction, transformation, cataloging, and governance is a complex, time-consuming process that needs to align with corporate data policies and governance frameworks.
AWS provides several services to support this; the following diagram illustrates these at a high level. For a more detailed description, see Scaling AI and Machine Learning Workloads with Ray on AWS and Build a RAG data ingestion pipeline for large scale ML workloads.

This workflow includes the following steps:
- Data can be securely transferred to AWS using either custom or existing tools or the AWS Transfer family. You can use AWS Identity and Access Management (IAM) and AWS PrivateLink to control and secure access to data and generative AI resources, making sure data remains within the organization’s boundaries and complies with the relevant regulations.
- When the data is in Amazon S3, you can use AWS Glue to extract and transform data (for example, into Parquet format) and store metadata about the ingested data, facilitating data governance and cataloging.
- The third component is the GPU cluster, which could potentially be a Ray cluster. You can employ various orchestration engines, such as AWS Step Functions, Amazon SageMaker Pipelines, or AWS Batch, to run the jobs (or create pipelines) to create embeddings and ingest the data into a data store or vector store.
- Embeddings can be stored in a vector store such as OpenSearch, enabling efficient retrieval and querying. Alternatively, you can use a solution such as Amazon Bedrock Knowledge Bases to ingest data from Amazon S3 or other data sources, enabling seamless integration with generative AI solutions.
- You can use Amazon DataZone to manage access control to the raw data stored in Amazon S3 and the vector store, enforcing role-based or fine-grained access control for data governance.
- For cases where you need a semantic understanding of your data, you can use Amazon Kendra for intelligent enterprise search. Amazon Kendra has inbuilt ML capabilities and is easy to integrate with various data sources like S3, making it adaptable for different organizational needs.
The choice of which components to use will depend on the specific requirements of the solution, but a consistent solution should exist for all data management to be codified into blueprints (discussed in the following section).
Provide managed infrastructure patterns and blueprints for models, prompt catalogs, APIs, and access control guidelines
There are a number of ways to build and deploy a generative AI solution. AWS offers key services such as Amazon Bedrock, Amazon Kendra, OpenSearch Service, and more, which can be configured to support multiple generative AI use cases, such as text summarization, Retrieval Augmented Generation (RAG), and others.
The simplest way is to allow each team who needs to use generative AI to build their own custom solution on AWS, but this will inevitably increase costs and cause organization-wide irregularities. A more scalable option is to have a centralized team build standard generative AI solutions codified into blueprints or constructs and allow teams to deploy and use them. This team can provide a platform that abstracts away these constructs with a user-friendly and integrated API and provide additional services such as LLMOps, data management, FinOps, and more. The following diagram illustrates these options.

Establishing blueprints and constructs for generative AI runtimes, APIs, prompts, and orchestration such as LangChain, LiteLLM, and so on will simplify adoption of generative AI and increase overall safe usage. Offering standard APIs with access controls, consistent AI, and data and cost management makes usage straightforward, cost-efficient, and secure.
For more information about how to enforce isolation of resources in a multi-tenant architecture and key patterns in isolation strategies while building solutions on AWS, refer to the whitepaper SaaS Tenant Isolation Strategies.
Conclusion
By focusing on the operational excellence pillar of the Well-Architected Framework from a generative AI lens, enterprises can scale their generative AI initiatives with confidence, building solutions that are secure, cost-effective, and compliant. Introducing a standardized skeleton framework for generative AI runtimes, prompts, and orchestration will empower your organization to seamlessly integrate generative AI capabilities into your existing workflows.
As a next step, you can establish proactive monitoring and alerting, helping your enterprise swiftly detect and mitigate potential issues, such as the generation of biased or harmful output.
Don’t wait—take this proactive stance towards adopting the best practices. Conduct regular audits of your generative AI systems to maintain ethical AI practices. Invest in training your team on the generative AI operational excellence techniques. By taking these actions now, you’ll be well positioned to harness the transformative potential of generative AI while navigating the complexities of this technology wisely.
About the Authors
 Akarsha Sehwag is a Data Scientist and ML Engineer in AWS Professional Services with over 5 years of experience building ML based services and products. Leveraging her expertise in Computer Vision and Deep Learning, she empowers customers to harness the power of the ML in AWS cloud efficiently. With the advent of Generative AI, she worked with numerous customers to identify good use-cases, and building it into production-ready solutions. Her diverse interests span development, entrepreneurship, and research.
Akarsha Sehwag is a Data Scientist and ML Engineer in AWS Professional Services with over 5 years of experience building ML based services and products. Leveraging her expertise in Computer Vision and Deep Learning, she empowers customers to harness the power of the ML in AWS cloud efficiently. With the advent of Generative AI, she worked with numerous customers to identify good use-cases, and building it into production-ready solutions. Her diverse interests span development, entrepreneurship, and research.
 Malcolm Orr is a principal engineer at AWS and has a long history of building platforms and distributed systems using AWS services. He brings a structured – systems, view to generative AI and is helping define how customers can adopt GenAI safely, securely and cost effectively across their organization.
Malcolm Orr is a principal engineer at AWS and has a long history of building platforms and distributed systems using AWS services. He brings a structured – systems, view to generative AI and is helping define how customers can adopt GenAI safely, securely and cost effectively across their organization.
 Tanvi Singhal is a Data Scientist within AWS Professional Services. Her skills and areas of expertise include data science, machine learning, and big data. She supports customers in developing Machine learning models and MLops solutions within the cloud. Prior to joining AWS, she was also a consultant in various industries such as Transportation Networking, Retail and Financial Services. She is passionate about enabling customers on their data/AI journey to the cloud.
Tanvi Singhal is a Data Scientist within AWS Professional Services. Her skills and areas of expertise include data science, machine learning, and big data. She supports customers in developing Machine learning models and MLops solutions within the cloud. Prior to joining AWS, she was also a consultant in various industries such as Transportation Networking, Retail and Financial Services. She is passionate about enabling customers on their data/AI journey to the cloud.
 Zorina Alliata is a Principal AI Strategist, working with global customers to find solutions that speed up operations and enhance processes using Artificial Intelligence and Machine Learning. Zorina helps companies across several industries identify strategies and tactical execution plans for their AI use cases, platforms, and AI at scale implementations.
Zorina Alliata is a Principal AI Strategist, working with global customers to find solutions that speed up operations and enhance processes using Artificial Intelligence and Machine Learning. Zorina helps companies across several industries identify strategies and tactical execution plans for their AI use cases, platforms, and AI at scale implementations.
Source link
lol