Aerospace companies face a generational workforce challenge today. With the strong post-COVID recovery, manufacturers are committing to record production rates, requiring the sharing of highly specialized domain knowledge across more workers. At the same time, maintaining the headcount and experience level of the workforce is increasingly challenging, as a generation of subject matter experts (SMEs) retires and increased fluidity characterizes the post-COVID labor market. This domain knowledge is traditionally captured in reference manuals, service bulletins, quality ticketing systems, engineering drawings, and more, but the quantity and complexity of documents is growing and takes time to learn. You simply can’t train new SMEs overnight. Without a mechanism to manage this knowledge transfer gap, productivity across all phases of the lifecycle might suffer from losing expert knowledge and repeating past mistakes.
Generative AI is a modern form of machine learning (ML) that has recently shown significant gains in reasoning, content comprehension, and human interaction. It can be a significant force multiplier to help the human workforce quickly digest, summarize, and answer complex questions from large technical document libraries, accelerating your workforce development. AWS is uniquely positioned to help you address these challenges through generative AI, with a broad and deep range of AI/ML services and over 20 years of experience in developing AI/ML technologies.
This post shows how aerospace customers can use AWS generative AI and ML-based services to address this document-based knowledge use case, using a Q&A chatbot to provide expert-level guidance to technical staff based on large libraries of technical documents. We focus on the use of two AWS services:
- Amazon Q can help you get fast, relevant answers to pressing questions, solve problems, generate content, and take actions using the data and expertise found in your company’s information repositories, code, and enterprise systems.
- Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Although Amazon Q is a great way to get started with no code for business users, Amazon Bedrock Knowledge Bases offers more flexibility at the API level for generative AI developers; we explore both these solutions in the following sections. But first, let’s revisit some basic concepts around Retrieval Augmented Generation (RAG) applications.
Generative AI constraints and RAG
Although generative AI holds great promise for automating complex tasks, our aerospace customers often express concerns about the use of the technology in such a safety- and security-sensitive industry. They ask questions such as:
- “How do I keep my generative AI applications secure?”
- “How do I make sure my business-critical data isn’t used to train proprietary models?”
- “How do I know that answers are accurate and only drawn from authoritative sources?” (Avoiding the well-known problem of hallucination.)
- “How can I trace the reasoning of my model back to source documents to build user trust?”
- “How do I keep my generative AI applications up to date with an ever-evolving knowledge base?”
In many generative AI applications built on proprietary technical document libraries, these concerns can be addressed by using the RAG architecture. RAG helps maintain the accuracy of responses, keeps up with the rapid pace of document updates, and provides traceable reasoning while keeping your proprietary data private and secure.
This architecture combines a general-purpose large language model (LLM) with a customer-specific document database, which is accessed through a semantic search engine. Rather than fine-tuning the LLM to the specific application, the document library is loaded with the relevant reference material for that application. In RAG, these knowledge sources are often referred to as a knowledge base.
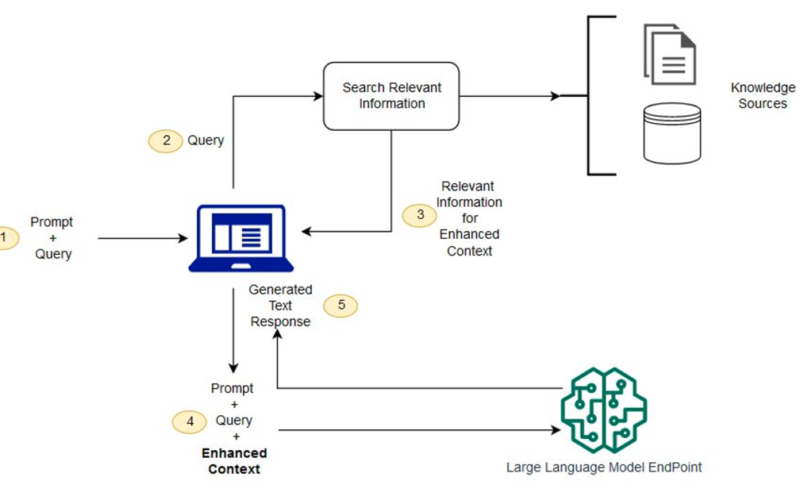
A high-level RAG architecture is shown in the following figure. The workflow includes the following steps:
- When the technician has a question, they enter it at the chat prompt.
- The technician’s question is used to search the knowledge base.
- The search results include a ranked list of most relevant source documentation.
- Those documentation snippets are added to the original query as context, and sent to the LLM as a combined prompt.
- The LLM returns the answer to the question, as synthesized from the source material in the prompt.
Because RAG uses a semantic search, it can find more relevant material in the database than just a keyword match alone. For more details on the operation of RAG systems, refer to Question answering using Retrieval Augmented Generation with foundation models in Amazon SageMaker JumpStart.
This architecture addresses the concerns listed earlier in few key ways:
- The underlying LLM doesn’t require custom training because the domain-specialized knowledge is contained in a separate knowledge base. As a result, the RAG-based system can be kept up to date, or retrained to completely new domains, simply by changing the documents in the knowledge base. This mitigates the significant cost typically associated with training custom LLMs.
- Because of the document-based prompting, generative AI answers can be constrained to only come from trusted document sources, and provide direct attribution back to those source documents to verify.
- RAG-based systems can securely manage access to different knowledge bases by role-based access control. Proprietary knowledge in generative AI remains private and protected in those knowledge bases.
AWS provides customers in aerospace and other high-tech domains the tools they need to rapidly build and securely deploy generative AI solutions at scale, with world-class security. Let’s look at how you can use Amazon Q and Amazon Bedrock to build RAG-based solutions in two different use cases.
Use case 1: Create a chatbot “expert” for technicians with Amazon Q
Aerospace is a high-touch industry, and technicians are the front line of that workforce. Technician work appears at every lifecycle stage for the aircraft (and its components), engineering prototype, qualification testing, manufacture, quality inspection, maintenance, and repair. Technician work is demanding and highly specialized; it requires detailed knowledge of highly technical documentation to make sure products meet safety, functional, and cost requirements. Knowledge management is a high priority for many companies, seeking to spread domain knowledge from experts to junior employees to offset attrition, scale production capacity, and improve quality.
Our customers frequently ask us how they can use customized chatbots built on customized generative AI models to automate access to this information and help technicians make better-informed decisions and accelerate their development. The RAG architecture shown in this post is an excellent solution to this use case because it allows companies to quickly deploy domain-specialized generative AI chatbots built securely on their own proprietary documentation. Amazon Q can deploy fully managed, scalable RAG systems tailored to address a wide range of business problems. It provides immediate, relevant information and advice to help streamline tasks, accelerate decision-making, and help spark creativity and innovation at work. It can automatically connect to over 40 different data sources, including Amazon Simple Storage Service (Amazon S3), Microsoft SharePoint, Salesforce, Atlassian Confluence, Slack, and Jira Cloud.
Let’s look at an example of how you can quickly deploy a generative AI-based chatbot “expert” using Amazon Q.
- Sign in to the Amazon Q console.
If you haven’t used Amazon Q before, you might be greeted with a request for initial configuration.
- Under Connect Amazon Q to IAM Identity Center, choose Create account instance to create a custom credential set for this demo.
- Under Select a bundle to get started, under Amazon Q Business Lite, choose Subscribe in Q Business to create a test subscription.
If you have previously used Amazon Q in this account, you can simply reuse an existing user or subscription for this walkthrough.

- After you create your AWS IAM Identity Center and Amazon Q subscription, choose Get started on the Amazon Q landing page.

- Choose Create application.
- For Application name, enter a name (for example,
my-tech-assistant). - Under Service access, select Create and use a new service-linked role (SLR).
- Choose Create.
This creates the application framework.

- Under Retrievers, select Use native retriever.
- Under Index provisioning, select Starter for a basic, low-cost retriever.
- Choose Next.

Next, we need to configure a data source. For this example, we use Amazon S3 and assume that you have already created a bucket and uploaded documents to it (for more information, see Step 1: Create your first S3 bucket). For this example, we have uploaded some public domain documents from the Federal Aviation Administration (FAA) technical library relating to software, system standards, instrument flight rating, aircraft construction and maintenance, and more.
- For Data sources, choose Amazon S3 to point our RAG assistant to this S3 bucket.

- For Data source name, enter a name for your data source (independent of the S3 bucket name, such as my-faa-docs).
- Under IAM role, choose Create new service role (Recommended).
- Under Sync scope, choose the S3 bucket where you uploaded your documents.
- Under Sync run schedule, choose Run on demand (or another option, if you want your documents to be re-indexed on a set schedule).
- Choose Add data source.
- Leave the remaining settings as default and choose Next to finish adding your Amazon S3 data source.

Finally, we need to create user access permissions to our chatbot.
- Under Add groups and users, choose Add groups and users.
- In the popup that appears, you can choose to either create new users or select existing ones. If you want to use an existing user, you can skip the following steps:
- Select Add new users, then choose Next.
- Enter the new user information, including a valid email address.
An email will be sent to that address with a link to validate that user.
- Now that you have a user, select Assign existing users and groups and choose Next.
- Choose your user, then choose Assign.

You should now have a user assigned to your new chatbot application.
- Under Web experience service access, select Create and use a new service role.
- Choose Create application.

You now have a new generative AI application! Before the chatbot can answer your questions, you have to run the indexer on your documents at least one time.
- On the Applications page, choose your application.

- Select your data source and choose Sync now.
The synchronization process takes a few minutes to complete.
- When the sync is complete, on the Web experience settings tab, choose the link under Deployed URL.

If you haven’t yet, you will be prompted to log in using the user credentials you created; use the email address as the user name.
Your chatbot is now ready to answer technical questions on the large library of documents you provided. Try it out! You’ll notice that for each answer, the chatbot provides a Sources option that indicates the authoritative reference from which it drew its answer.

Our fully customized chatbot required no coding, no custom data schemas, and no managing of underlying infrastructure to scale! Amazon Q fully manages the infrastructure required to securely deploy your technician’s assistant at scale.
Use case 2: Use Amazon Bedrock Knowledge Bases
As we demonstrated in the previous use case, Amazon Q fully manages the end-to-end RAG workflow and allows business users to get started quickly. But what if you need more granular control of parameters related to the vector database, chunking, retrieval, and models used to generate final answers? Amazon Bedrock Knowledge Bases allows generative AI developers to build and interact with proprietary document libraries for accurate and efficient Q&A over documents. In this example, we use the same FAA documents as before, but this time we set up the RAG solution using Amazon Bedrock Knowledge Bases. We demonstrate how to do this using both APIs and the Amazon Bedrock console. The full notebook for following the API-based approach can be downloaded from the GitHub repo.
The following diagram illustrates the architecture of this solution.

Create your knowledge base using the API
To implement the solution using the API, complete the following steps:
- Create a role with the necessary policies to access data from Amazon S3 and write embeddings to Amazon OpenSearch Serverless. This role will be used by the knowledge base to retrieve relevant chunks for OpenSearch based on the input query.
- Create an empty OpenSearch Serverless index to store the document embeddings and metadata. OpenSearch Serverless is a fully managed option that allows you to run petabyte-scale workloads without managing clusters.
- With the OpenSearch Serverless index set up, you can now create the knowledge base and associate it with a data source containing our documents. For brevity, we haven’t included the full code; to run this example end-to-end, refer to the GitHub repo.
The ingestion job will fetch documents from the Amazon S3 data source, preprocess and chunk the text, create embeddings for each chunk, and store them in the OpenSearch Serverless index.
- With the knowledge base populated, you can now query it using the
RetrieveAndGenerateAPI and get responses generated by LLMs like Anthropic’s Claude on Amazon Bedrock:
The RetrieveAndGenerate API converts the query into an embedding, searches the knowledge base for relevant document chunks, and generates a response by providing the retrieved context to the specified language model. We asked the question “How are namespaces registered with the FAA for service providers?” Anthropic’s Claude 3 Sonnet uses the chunks retrieved from our OpenSearch vector index to answer as follows:
To register a namespace with the FAA as a service provider, you need to follow these steps:
- Develop the namespaces metadata according to FAA-STD-063 and submit it for registration in the FAA Data Registry (FDR).
- The FDR registrar will perform the namespace registration function. The specific process for
developing and registering a namespace in the FDR involves: - Searching the FDR for an existing namespace that matches your business domain. If none exists, work
with the FDR registrar to create a new one. - Create and document the new namespace according to FAA-STD-063, following the guidelines for
organization, web service, or taxonomy namespaces. - Register the namespace in the FDR by either filling out a registration form and submitting it to the FDR
registrar, or requesting access to enter the metadata directly into the FDR.
Create your knowledge base on the Amazon Bedrock console
If you prefer, you can build the same solution in Amazon Bedrock Knowledge Bases using the Amazon Bedrock console instead of the API-based implementation shown in the previous section. Complete the following steps:
- Sign in to your AWS account.
- On the Amazon Bedrock console, choose Get started.

As a first step, you need to set up your permissions to use the various LLMs in Amazon Bedrock.
- Choose Model access in the navigation pane.
- Choose Modify model access.

- Select the LLMs to enable.
- Choose Next¸ then choose Submit to complete your access request.
You should now have access to the models you requested.

Now you can set up your knowledge base.
- Choose Knowledge bases under Builder tools in the navigation pane.
- Choose Create knowledge base.

- On the Provide knowledge base details page, keep the default settings and choose Next.
- For Data source name, enter a name for your data source or keep the default.
- For S3 URI, choose the S3 bucket where you uploaded your documents.
- Choose Next.

- Under Embeddings model, choose the embeddings LLM to use (for this post, we choose Titan Text Embeddings).
- Under Vector database, select Quick create a new vector store.
This option uses OpenSearch Serverless as the vector store.
- Choose Next.

- Choose Create knowledge base to finish the process.
Your knowledge base is now set up! Before interacting with the chatbot, you need to index your documents. Make sure you have already loaded the desired source documents into your S3 bucket; for this walkthrough, we use the same public-domain FAA library referenced in the previous section.
- Under Data source, select the data source you created, then choose Sync.
- When the sync is complete, choose Select model in the Test knowledge base pane, and choose the model you want to try (for this post, we use Anthropic Claude 3 Sonnet, but Amazon Bedrock gives you the flexibility to experiment with many other models).

Your technician’s assistant is now set up! You can experiment with it using the chat window in the Test knowledge base pane. Experiment with different LLMs and see how they perform. Amazon Bedrock provides a simple API-based framework to experiment with different models and RAG components so you can tune them to help meet your requirements in production workloads.

Clean up
When you’re done experimenting with the assistant, complete the following steps to clean up your created resources to avoid ongoing charges to your account:
- On the Amazon Q Business console, choose Applications in the navigation pane.
- Select the application you created, and on the Actions menu, choose Delete.
- On the Amazon Bedrock console, choose Knowledge bases in the navigation pane.
- Select the knowledge base you created, then choose Delete.
Conclusion
This post showed how quickly you can launch generative AI-enabled expert chatbots, trained on your proprietary document sets, to empower your workforce across specific aerospace roles with Amazon Q and Amazon Bedrock. After you have taken these basic steps, more work will be needed to solidify these solutions for production. Future editions in this “GenAI for Aerospace” series will explore follow-up topics, such as creating additional security controls and tuning performance for different content.
Generative AI is changing the way companies address some of their largest challenges. For our aerospace customers, generative AI can help with many of the scaling challenges that come from ramping production rates and the skills of their workforce to match. This post showed how you can apply this technology to expert knowledge challenges in various functions of aerospace development today. The RAG architecture shown can help meet key requirements for aerospace customers: maintaining privacy of data and custom models, minimizing hallucinations, customizing models with private and authoritative reference documents, and direct attribution of answers back to those reference documents. There are many other aerospace applications where generative AI can be applied: non-conformance tracking, business forecasting, bid and proposal management, engineering design and simulation, and more. We examine some of these use cases in future posts.
AWS provides a broad range of AI/ML services to help you develop generative AI solutions for these use cases and more. This includes newly announced services like Amazon Q, which provides fast, relevant answers to pressing business questions drawn from enterprise data sources, with no coding required, and Amazon Bedrock, which provides quick API-level access to a wide range of LLMs, with knowledge base management for your proprietary document libraries and direct integration to external workflows through agents. AWS also offers competitive price-performance for AI workloads, running on purpose-built silicon—the AWS Trainium and AWS Inferentia processors—to run your generative AI services in the most cost-effective, scalable, simple-to-manage way. Get started on addressing your toughest business challenges with generative AI on AWS today!
For more information on working with generative AI and RAG on AWS, refer to Generative AI. For more details on building an aerospace technician’s assistant with AWS generative AI services, refer to Guidance for Aerospace Technician’s Assistant on AWS.
About the authors
 Peter Bellows is a Principal Solutions Architect and Head of Technology for Commercial Aviation in the Worldwide Specialist Organization (WWSO) at Amazon Web Services (AWS). He leads technical development for solutions across aerospace domains, including manufacturing, engineering, operations, and security. Prior to AWS, he worked in aerospace engineering for 20+ years.
Peter Bellows is a Principal Solutions Architect and Head of Technology for Commercial Aviation in the Worldwide Specialist Organization (WWSO) at Amazon Web Services (AWS). He leads technical development for solutions across aerospace domains, including manufacturing, engineering, operations, and security. Prior to AWS, he worked in aerospace engineering for 20+ years.
 Shreyas Subramanian is a Principal Data Scientist and helps customers by using Machine Learning to solve their business challenges using the AWS platform. Shreyas has a background in large scale optimization and Machine Learning, and in use of Machine Learning and Reinforcement Learning for accelerating optimization tasks.
Shreyas Subramanian is a Principal Data Scientist and helps customers by using Machine Learning to solve their business challenges using the AWS platform. Shreyas has a background in large scale optimization and Machine Learning, and in use of Machine Learning and Reinforcement Learning for accelerating optimization tasks.
 Priyanka Mahankali is a Senior Specialist Solutions Architect for Aerospace at AWS, bringing over 7 years of experience across the cloud and aerospace sectors. She is dedicated to streamlining the journey from innovative industry ideas to cloud-based implementations.
Priyanka Mahankali is a Senior Specialist Solutions Architect for Aerospace at AWS, bringing over 7 years of experience across the cloud and aerospace sectors. She is dedicated to streamlining the journey from innovative industry ideas to cloud-based implementations.
Source link
lol