In the high-stakes world of data science and AI, project success is far from guaranteed. As leaders in this field, we’re acutely aware of the multifaceted challenges that can derail even the most promising initiatives. From models falling short of requirements to production failures with real-world data, the path to success is fraught with potential pitfalls.
The complexity of data science projects demands more than traditional project management approaches. It requires a strategic mindset focused on uncertainty reduction and the ability to “fail fast.” In this article, we’ll explore seven top tips for managing your data science project effectively, helping you navigate the complexities and maximize your chances of success.
The Uncertainty Reduction Approach
Consider project success as a function of minimizing uncertainties. Our primary objective should be to identify and address the most significant uncertainties with the least resource expenditure, thereby optimizing our risk-reward ratio.
Regardless of whether you’re working on user-facing features, marketing initiatives, financial models, or any other operational area, a data science project can be modeled with the same core components: Objective, Requirements, Stakeholders, Deadline, and Resources. Understanding these components is crucial for effective project management.
While various project management methodologies like Waterfall, Scrum, Agile, or CRISP-DM can be applied based on your company’s culture and needs, the guiding principle should always be to reduce uncertainty. As leaders, we must cultivate an instinct for identifying the most ambiguous, risky, or potentially problematic aspects of a project. Prioritizing these challenges not only mitigates risks but can also save substantial resources by avoiding work on ultimately unviable paths.
In this article, I will share my 7 top tips for reducing uncertainty that have proven most effective for me in leading data science teams.
Tip 1: Time-box your research to focus curiosity
Limiting the time for research is one of the tactics that I have applied throughout my career that has yielded the most benefits. Data scientists are professionals driven by curiosity and the desire to solve intellectually challenging problems. This is an amazing quality that has made the field as successful as it is today, but it can also lead to these employees going down rabbit-holes and digging into topics with diminishing returns on the overall objective of the project. This can cause scope creep and resource allocation issues if not managed effectively.
Research spikes provide a structured framework to harness this curiosity productively. This technique serves multiple purposes:
- Rapid knowledge acquisition
- Team engagement
- Strategic alignment: of cutting-edge technologies with business objectives.
Use it as a motivation and encouragement tool
When starting a new project in a field that is rather new for your team, this is a very good way for them to understand the state-of-the-art, industry standards, and to build a bond with the field, often improving motivation. This last bit is quite important as it helps data scientists and machine learning engineers put everything around them into perspective. There has typically been a lot of FOMO (Fear of Missing Out) in the field when you’re a professional not working on cutting-edge technologies (at the time of writing this article, Generative AI is the coolest new kid on the block). Reading papers and exploring SOTA (State of the Art) techniques trigger a slight excitement as they allow the professional to dive into a topic and understand that there are also other people willing to solve it.
In my experience, it is always best to do these research spikes in the situation I described above when you have to work on a project that is tackling a new area of knowledge. It is often the case that the problem you aim to solve with machine learning and data science techniques has already been approached in the past by experts in the specific field, who are not necessarily data scientists. Examples of such fields include financial modeling, cognitive psychology, algorithmic trading, and many others. Leveraging existing domain knowledge can significantly accelerate your team’s progress and prevent reinventing the wheel.
To effectively implement time-boxed research spikes
- Define Clear Objectives: Set specific goals like “Write a review of the state-of-the-art in X”, “Understand successful feature engineering techniques for Y”, or “Explore approaches to solve Z”.
- Establish Time Constraints: This is crucial as it serves as the main deterrent against diving into rabbit holes, ensuring the goal remains focused and achievable.
- Facilitate Knowledge Sharing: Schedule a debrief session post-research to disseminate findings across the team. This helps in knowledge distribution and can spark new ideas or perspectives from team members.
- Use Time Tracking: Use techniques such as Pomodoro in order to continuously assess what you’re working on. Having intense focused time slots and then brief pauses can help to verify if you’re still spending time on what matters.
This technique fits very well in the initial stage of the first diamond from the widely known *Double Diamond,* a visual representation of innovation processes. It aligns with the ‘Discover’ phase, where teams explore the problem space broadly before narrowing down to specific solutions and enables:
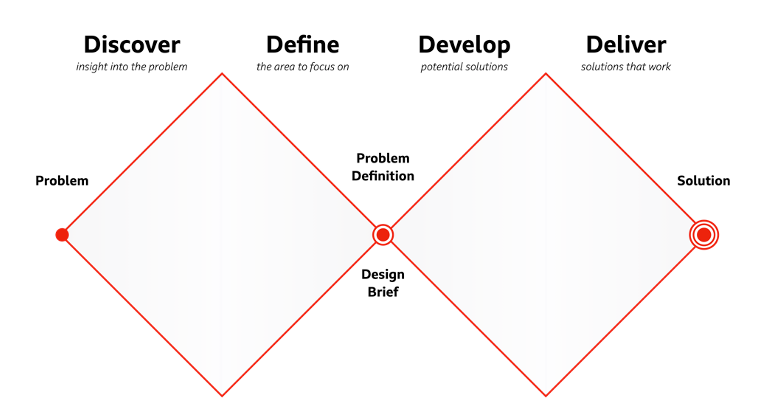
- Acceleration of proof-of-concept development.
- Identification of potential roadblocks early, mitigating project risks.
- Fostering a culture of continuous learning and innovation.
- Improving resource allocation and project planning through enhanced problem understanding.
This tip has been invaluable for me and my team. It has helped us build a lot of confidence on the problem to tackle. With a wide perspective of the solution space, it becomes easier to achieve an optimal solution.
Tip 2: Hack your way through complexity
Throughout my career, leveraging 1-2 day hackathons has consistently proven to be an invaluable tool for tackling high-uncertainty problems while fostering innovation and team cohesion.
Why doing hackathons can be transformative
Hackathons, when strategically implemented, serve as catalysts for breakthrough thinking. By creating an intense, focused environment where your team can step away from day-to-day tasks and dive deep into complex issues, you can be effective at:
- Confronting ambiguous challenges
- Exploring innovative solutions that encourage out-of-the-box thinking and rapid prototyping
- Breaking through roadblocks to overcome stagnation in long-term projects
In the same vein as time-boxed research spikes, the sense of urgency in these events is crucial. It leads to surprising innovations and solutions. It also prevents the event from becoming a drain on resources or a distraction for other projects.
Hackathons are a very useful fun tool to overcome a challenge, but they should still be planned carefully. Usually, the best stage in a project lifecycle to run a hackathon is at the very start. It helps to detect if there is a signal soon enough. In the later stages it may also be interesting to run shorter hackathons to tackle specific problems.
To maximize the effectiveness of these events, it’s necessary to:
- Define Clear Objectives: Goals should be challenging. We need to be aware that the hackathon won’t solve the problem fully, but at least, the biggest pain points and ambiguous steps should be tackled.
- Diverse Team Composition: Including members from various specialties can be quite rewarding. If you include stakeholders or professionals from other fields, such as product designers, or subject matter experts, it can help to narrow the focus on solving the end-user needs.
- Structure Teams: There are very different ways in which you can organize a hackathon. Given that you have a goal to achieve, you can:
- Set up two teams aiming to achieve the same goal so that they compete on building the solution independently. This is very interesting both in situations where the base solution is not clear or when the objective is to make incremental improvements. Solutions from both teams can be compatible, thus improving the overall system effectiveness, or not, but either way, the competition factor adds an edge to the intensity of the event.
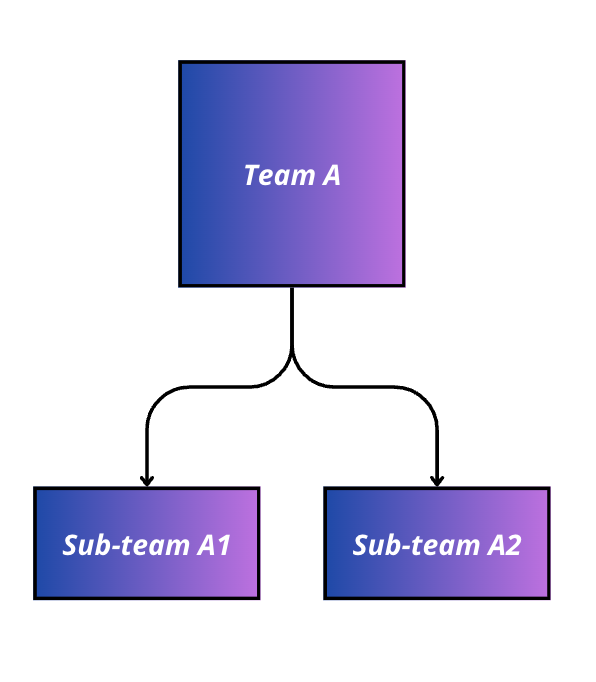
- Divide the team into sub-components-focused teams for the solution. If the main components of what needs to be built are clear, a very effective approach to cover an end-to-end solution is to divide the team into two or more teams, each focused on solving one sub-problem of the whole objective. This way of setting up a hackathon encourages more focused solutions and improves team cohesion as integrations between components are required. This is typically done for problems which need a system composed of different elements, for example chatbots, recommender systems, etc.
- Inspired by security hacking, divide the team into “attackers” and “defenders”. Let one team build a solution and the other aim to break it. This setup is particularly effective in situations in which the data science or AI output quality is critical. For example, when building a conversational agent for handling important personal topics for customers.
- Provide Necessary Resources: Preparation is fundamental for hackathons.
- Make sure that data scientists’ and/or machine learning engineers’ environments are 100% set up and ready for hacking when the event starts.
- Outline and review the necessary datasets for engineers to build models or analyze.
- Create an introductory presentation with a guiding agenda of the hackathon and explain the goals and team setups. Schedule placeholders for lunch and presentations for participants.
- Prepare beverages and food for participants! As these events are quite intense, make sure you provide enough water, coffee, and healthy snacks such as dark chocolate and low-sugar energy bars that support brain function. Avoid sugary foods to prevent spikes and crashes that can lead to fatigue.
- Clear Deliverables: Make it clear what the expected outputs of the hackathon are, whether it’s a terminal application, a Streamlit app, a written document, or a slide deck, it needs to be explicit.
- Follow-up Integration: Have a plan to incorporate valuable insights into ongoing projects.
After finishing a hackathon, it’s recommended to do a post-hackathon retrospective to discuss what went well, what didn’t, and the lessons learned. Also, recognise and award outstanding contributions and innovative ideas and document ideas that were not fully developed, which can be valuable seeds for future projects and innovations.
It’s important to note that while hackathons can lead to innovative solutions, they should complement, not replace, structured development processes. They are strategic tools to unlock potential solutions that can then be refined and implemented within your regular project framework. By conducting these hackathons, you can solve immediate problems and also cultivate an agile, innovative team culture capable of tackling challenging aspects of data science projects.
From my experience, hackathons have yielded very valuable insights and assets for the problems at hand. My preferred approach is to divide the team into smaller teams, typically with 2 or 3 people max in each. This makes it possible to tackle different problems or components of the goal to achieve or system to build.
Tip 3: Build bridges with stakeholders
In the complex ecosystem of data science projects, stakeholder engagement is not just a best practice—it’s a critical success factor. Throughout my career leading data science initiatives, I’ve found that building strong relationships with stakeholders is often the differentiator between projects that deliver transformative value and those that fall short of expectations. Data science is still not yet widely understood, therefore, your goal is to bridge the gap and evangelize. Make sure that stakeholders understand what data science is capable of.
Effective stakeholder engagement goes beyond mere project updates. It’s about creating a shared vision, aligning objectives, and fostering a collaborative environment where data science insights can truly drive business outcomes. Here’s my take on how to approach this crucial aspect:
When approaching stakeholders, identify and prioritize who to engage with
Map out all potential stakeholders across different business units and levels of seniority and assess their influence on the project and the potential impact of the project on their areas. Then, prioritize engagement based on this assessment, ensuring you’re investing time where it matters most.
Understand stakeholder motivations and incentives
Dive deep into the incentives that drive your stakeholders. This understanding is crucial for effective communication and alignment. Consider both organizational and personal motivations. For instance, a marketing director might be driven by market share goals, while also being motivated by recognition for innovative approaches. Use frameworks like the Incentives Theory of Motivation to structure your approach to stakeholder engagement.
This is often referred to as politics in the corporate jargon, but you need to understand that it’s the reality. Businesses are driven by people, and people have desires and motivations. Acknowledging them and being able to use them to communicate and engage is a win-win situation.
Tailor your communication strategy
Develop a communication plan that addresses the needs and preferences of different stakeholder groups. For technical stakeholders, focus on methodologies and data integrity. For business-oriented stakeholders, emphasize potential ROI and strategic alignment. Consider using data visualization tools to make complex concepts more accessible to non-technical stakeholders.
Make sure stakeholders receive the information they need at the right moment. Executives have to make decisions often about resource allocation and they need signals from managers to know the status of the different projects and initiatives to take informed actions.
Always involve stakeholders in key decisions
Create touch points throughout the project lifecycle for stakeholder input. Use techniques like decision matrices or multi-voting in workshops to involve stakeholders in critical choices. This involvement not only improves decision quality but also increases stakeholder buy-in.
Make sure stakeholders are invited to demos, sprint reviews and keep a culture of full transparency.
Manage stakeholders’ expectations proactively
Be transparent about project capabilities, limitations, and potential risks. Regularly revisit and realign on project goals and success metrics. Use scenario planning to prepare stakeholders for different possible outcomes.
Celebrate successes together
Recognise the contributions of stakeholders in project successes. Use success stories to build momentum for future initiatives. Create opportunities for shared learning and reflection on what worked well.
Remember, in data science projects, technical excellence alone is not enough. Your ability to engage stakeholders effectively can make the difference between a project that delivers theoretical value and one that drives real business transformation. By investing time and effort in building strong stakeholder relationships, you’re not just ensuring the success of your current project—you’re laying the groundwork for future data science initiatives and elevating the strategic importance of data science within your organization.
Effective stakeholder engagement is an ongoing process that requires emotional intelligence, strategic thinking, and adaptability. As leaders in data science, our role extends beyond technical oversight; we must be adept at navigating the human elements that ultimately determine the impact and adoption of our work. By mastering this skill, you position yourself and your team as indispensable partners in driving data-informed decision-making across the enterprise.
From my experience, the closer you are to stakeholders, the most successful your project can be. I could not assure if this is a causal relationship, but I assume it is just by seeing the high correlation and the moderate effort this requires.
Tip 4: Assemble a dream team of diverse talents
The field of data science is very wide. It is crucial to assemble a team of professionals who can tackle your project end-to-end smoothly, efficiently, and with reliability. Depending on the nature of the project you have to lead, different hard skills would be needed. Are you developing cutting-edge AI models, or are you more focused on translating data into actionable business insights? Your project’s true nature should guide your hiring decisions, not just industry buzzwords or trending job titles.
Remember when you were hands-on with the technical work? That experience is gold now. Use it to look beyond the résumé and job titles. A “data scientist” from one company might have the exact skills you’d expect from a “machine learning engineer” in another. It’s the skills and experience that count, not the label.
In your position, you’ve likely seen projects succeed and fail. Think about the teams behind those outcomes. Often, the most successful ones had a mix of specialists and versatile players. The specialist might crack that complex algorithm you need, but it’s the jack-of-all-trades who often connect the dots across the project.
Consider your project’s life cycle too. Are you in the thrilling early stages where you need creative problem-solvers who can wear multiple hats? Or are you scaling up, requiring more specialized roles to fine-tune and maintain your systems?
Don’t forget the importance of soft skills. We’ve all worked with brilliant minds who couldn’t explain their work to save their lives. In today’s cross-functional teams, the ability to communicate complex ideas simply is just as crucial as technical prowess.
Lastly, think long-term. The field of data science moves at breakneck speed. The team you build should not only meet today’s needs but also have the potential to tackle tomorrow’s challenges. Look for curious minds, quick learners, and those with a passion for staying at the cutting edge. By focusing on these aspects, you’re not just filling positions – you’re building a dynamic, adaptable team that can navigate the complex waters of data science projects.
This is probably the tip that is more difficult to materialize. Is not always possible to assemble a new team for every project. In most situations, you have to adapt the projects to the team you’ve encountered. But these suggestions are also useful to drive the professional development of the group and build the skills needed to tackle those projects.
Tip 5: Dive deep into the problem’s core
The deeper knowledge you have about the problem, the better tools you will have to solve it. Throughout my career, I’ve observed that projects that fail to deliver value aren’t typically hindered by technical limitations, but by a misalignment between the solution and the core business problem.
One important note to add here is that there is a clear difference between diving deep into the problem’s core and going down a rabbit hole. Understanding the core of the issue is radically different from losing yourself in the corner cases, unproductive or low-value issues. As specified below, it is always necessary to understand the Why. Why your customer has raised the need to do this project, why is this problem difficult to solve, etc. Asking yourself these questions and eventually resolving them will put you in a better situation to complete the project efficiently.
Hopefully, using the above tips will make you quite knowledgeable of the problem at hand, but there are other ways in which you can achieve this. Developing this deep understanding is not just about gathering requirements; it’s about becoming a domain expert in the problem space.
Use root cause analysis
Conduct 5 Why’s-like techniques to dig beneath surface-level statements and set up workshops with subject matter experts to uncover assumptions and potential biases.
Map the problem ecosystem
Create visual representations of how the problem intersects with several business processes and identify upstream and downstream impacts.
Quantify the problem
Try to quantify the monetary impact of solving the problem and always keep track of the ROI. Develop metrics that serve as a baseline for measuring improvement. This will help to prioritize efforts and justify resources.
Prototype and iterate
Follow a product management approach to solve the problem. Understand your user needs, prototype a solution, learn from how the users use it, iterate and refine the solution.
Foster a culture of curiosity
In terms of team leadership, encourage your team to ask probing questions and always challenge assumptions. Reward the people who bring new perspectives and lead by example. Demonstrate intellectual humility and openness to new ideas.
Investing time in understanding the problem is one of the key rewarding activities to reduce uncertainty. You may even discover that a machine learning system is not needed to solve the problem! I’ve experienced this many times, and only by delving into the problem did I find that we were just about to commit to building a solution that wasn’t needed.
Tip 6: Iterate, feedback, repeat
Iterative development for data science projects is not an easy task. The iterative capacity is given, in most cases, by the flexibility of the tooling and the code, the ability to easily evaluate and validate the model, and the establishment of effective feedback mechanisms.
Some of the key aspects that enable iterative development and feedback loops are:
A modular code architecture: Having different parts of the system modularised allows for easier updates and experimentation without affecting the entire system. Building decoupled tooling for dataset building, training code, evaluation code, and model building code allows for more flexible experimentation. This is because when each of these components is independent of the others and they are only tied to a shared input/output interface (in this case, passing around dataframes and model objects through classes and methods), making internal changes to one doesn’t affect the others.
Modularity is especially useful when you need to change, for example, the number of months to retrieve from the dataset, the ML algorithm to be trained, or any of the hyperparameters of it. Having this mindset paves the way for more reliable and reproducible results from experimentation.
Version control, lineage, and tracking: In data science, lineage is critical. A production ML system is composed of different elements that can change over time such as the different codebases and the different datasets used. MLOps tools such as Weights & Biases, Sagemaker Experiments, or MLFLow are great options to start with, they are mature and established tools. In my experience, the sooner your team gets used to these tools, the more reliable results you will have.
These tools help data scientists avoid, in most cases, issues about the true source of the model when debugging to investigate an issue in production. If you’re not able to go back in time and rebuild the exact same model that you have in production, then you have a lineage problem. It’s not only that regulations around ML are going to be enforcing these, but customers as well, specifically B2B businesses.
Enable feedback collection mechanisms: Having channels for collecting feedback from stakeholders or end users allows one to detect when it is necessary to review the ML system and how to refine it if needed. It can be done through in-app user feedback surveys, using rating mechanisms from ML or AI outputs such as star ratings or thumbs up and down, in-person surveys after exposure to the system, etc.
These tips are typically difficult to prioritize among the core direct value impact work. But I’d like to reinforce the importance of these principles. You will regret it if you don’t have them. Trust me.
Tip 7: Automate to accelerate
This is typically a controversial topic. The question of when to start automating processes in a project is not trivial. We have to be pragmatic and think that there will always be new projects in the future. Or there could be multiple data science projects running in parallel in your team or company.
Management is sometimes a game of objectives and restrictions and in this case, we have to balance resources and time effectively for immediate and future returns and instant or compound value added.
For this reason, automation in data science can be materialized in several forms. When the problem has already been disclosed as feasible, either because a prototype partially solved the problem or the roadmap to solve it is pretty straightforward (if there is low uncertainty), one could start working on automating different stuff.
Automate the experimentation process for quicker decision-making
For example, one of the most obvious parts is being able to automate the whole experimentation process. ML training processes can depend on a wide variety of factors such as the data selection process, the algorithm chosen for training, the training procedure, the hyperparameters of the algorithm, etc. Assuming a modular code as we introduced in the previous tip allows us to work on automations in a much smoother way. Joining components of the pipeline and building tooling around them to test it with different parameters is key to maximizing the likelihood of coming up with the best model possible.
Automate data quality and transformation processes
Another critical example of early automation is data preprocessing and feature engineering. As your team iterates on models, you’ll likely find yourself repeatedly performing similar data cleaning, transformation, and feature extraction tasks. By automating these processes early, you can significantly reduce the time spent on repetitive tasks and ensure consistency across experiments.
Consider implementing automated data quality checks as well. These can flag anomalies, missing values, or unexpected distributions in your datasets. This proactive approach not only saves time but also helps maintain data integrity throughout the project lifecycle.
Automate artifact tracking and reporting
Version control is another area where early automation pays dividends. Implement systems to track not just code changes, but also model versions, dataset iterations, and experiment configurations. This automation enables reproducibility and makes it easier to roll back to previous states if needed.
Reporting and visualization are often overlooked areas for automation. Developing templates and scripts for generating standardized reports on model performance, data insights, and project progress can greatly enhance communication with stakeholders and streamline decision-making processes.
While automating early requires an initial time investment, it sets the foundation for scalability. As your projects grow in complexity or your team expands, automation will prove invaluable. it allows new team members to onboard more quickly and enables experienced data scientists to focus on high-value, creative problem-solving rather than repetitive tasks.
However, it’s crucial to strike a balance. Over-automation too early in a project can lead to rigid systems that are difficult to adapt as requirements change. The key is to automate processes that are likely to remain stable throughout the project lifecycle while maintaining flexibility in areas where exploration and iteration are still needed.
By thoughtfully implementing automation early in your data science projects, you can create a more efficient, scalable, and robust workflow that positions your team for long-term success.
Conclusion
In the ever-evolving landscape of data science, success isn’t just about algorithms and datasets—it’s about strategic project management too! By embracing these seven tips, you’re not just managing projects; you’re orchestrating a symphony of innovation, collaboration, and value creation for your company!
Remember:
- Time-box your research to focus curiosity
- Hack your way through complexity
- Build bridges with stakeholders
- Assemble a dream team of diverse talents
- Dive deep into the problem’s core
- Iterate, feedback, repeat
- Automate to accelerate
Each of these strategies serves as a compass point, guiding you through the fog of uncertainty that often covers data science initiatives. By reducing ambiguity, fostering collaboration, and building agile processes, you’re not just completing projects—you’re transforming your organization’s data science capabilities.
As you implement these tips, you’ll find that managing data science projects becomes less about firefighting and more about fire-starting—igniting innovation, driving value, and positioning your team at the forefront of data-driven decision-making.
The future of data science is bright, and with these strategies in your toolkit, you’re well-equipped to lead the charge. So go forth, experiment boldly, fail fast, and succeed spectacularly!
Source link
lol