Couchbase says the new column store that it officially launched today on AWS will streamline analytics on “dormant” JSON data residing in its NoSQL database. The company also launched vector search capabilities in the mobile version of its database and the new free tier in the cloud.
Couchbase historically sought to split the difference between transactional and analytical databases by building a database designed for operational applications. While it was capable of executing analytic queries, particularly with the SQL++ extension that it added for JSON data, the Couchbase database was by no means an analytics database.
That story seems to be changing now that Couchbase has added a column store to the various modes that its flexible database can morph into.
Column stores are preferred for large-scale analytics work because of the way they store data. Instead of storing detailed data in rows, as a traditional relational database does, or in JSON documents, as the Couchbase’s traditional NoSQL database engine does, a column store stores detailed data in columns, which dramatically boosts performance for analytic workloads.
Most high-performance analytic databases store detailed data in columns. And, for the same reason, most high-performance transactional databases store detailed data in rows. Couchbase discussed the difference in a blog post earlier this year.
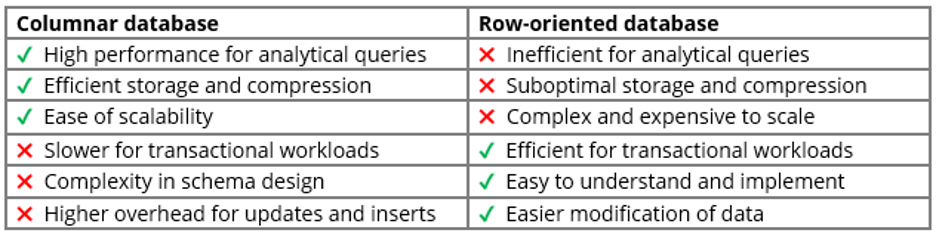
Row stores vs column stores (Image courtesy Couchbase)
The columnar gains are even bigger when dealing with JSON data, which is a semi-structured data format that’s much loved by developers thanks to its flexibility but which must be unpacked and normalized before traditional SQL analytics can work on it.
Couchbase had this to say about the JSON-vs-column store debate in a press release issued today:
“Many organizations, including Couchbase customers, have embraced the flexibility of JSON when building business-critical applications. However, while JSON is often the programmer’s preferred data format, it can be difficult to use for traditional analytic systems that expect data to conform to more rigid structures. Without formal structures, business intelligence teams spend too much time on data hygiene, and less on including operational JSON data in their analysis. This is why so much semi-structured JSON data remains dormant.”
Couchbase says Capella Columnar, which it first unveiled last fall during AWS re:Invent, helps users with the parsing, transforming, and persisting of JSON data into a columnar format, which eliminates the need for ETL. In addition to ingesting data from Couchbase’s JSON store, it’s also designed to ingest data from Kafka-based systems and any other JSON or SQL-based stores, including MongoDB, MySQL, and Postgres. Flat files stored in an object store like S3, such as CSV, Parquet, and AVRO files, can also be ingested into the column store, Couchbase says.
Once in the column format, Capella Columnar provides an MPP (massively parallel processing) engine to power SQL++ queries. The setup also includes a cost-based optimizer to help execute analytic queries in an efficient manner.
Capella Columnar runs separately from traditional Capella Server, which supports Couchbase’s traditional document and key-value stores. The separation of compute and storage provides performance isolation for both environments. This solution is only available on Capella running on AWS.
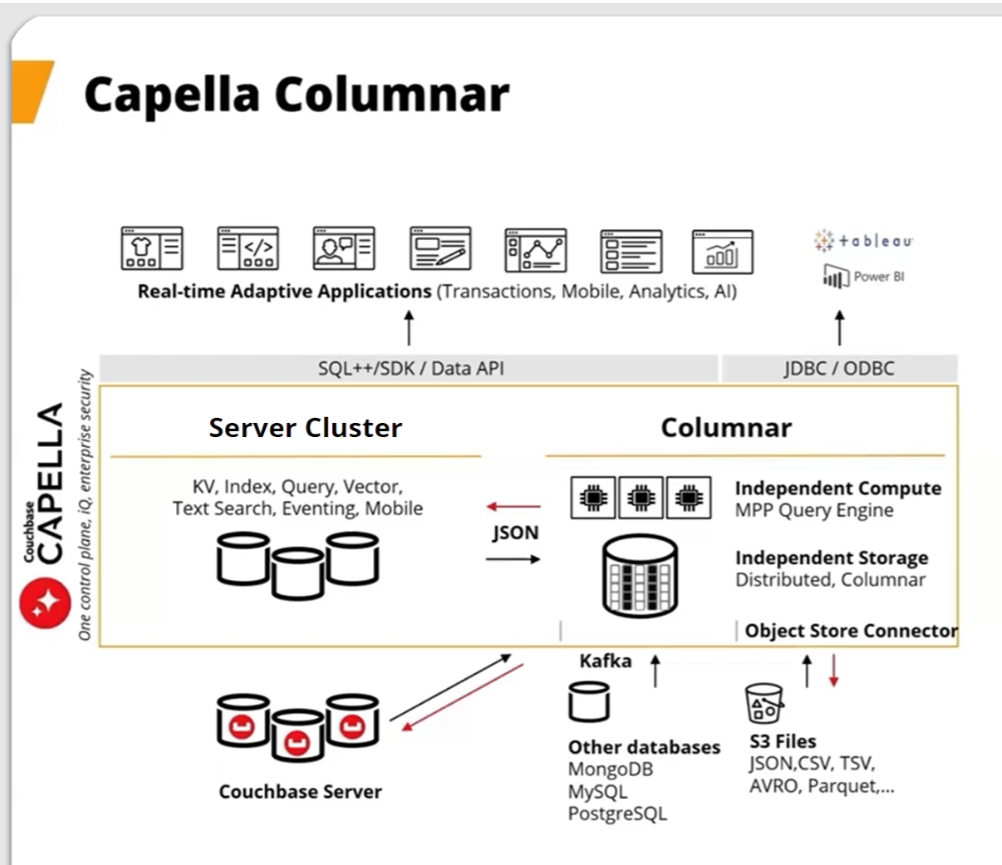
Capella Columnar architecture (Image courtesy Couchbase)
It’s all about empowering organizations to build adaptive applications that can respond to real-world scenarios in real time, according to Matt McDonough, SVP of product and partners at Couchbase.
“With the launch of Capella Columnar, we’re solving long-standing challenges in JSON data analytics, enabling businesses to seamlessly integrate insights into their operational applications,” he said in a press release.
The company has also done work to integrate Capella iQ, its AI-powered coding assistant. Capella iQ can automatically generate SQL++ queries for users, which the company says reduces the need for highly skilled BI developers. Once an important metric is calculated, Couchbase says, it can immediately be written back to the operational side of Capella for use as a metric within the application.
“This write-back problem has remained unaddressed by analytic systems for decades because it was too difficult to anticipate what a developer would do with it,” McDonough said. “Capella Columnar implements the solution, and the needs of AI-powered applications provide the motive.”
Couchbase also announced the addition of vector capabilities in Couchbase Lite, its embedded database for mobile and IoT applications. The addition of vector embeddings in Couchbase Lite will help Couchbase customers utilize semantic search in their applications, as well as to build generative AI capabilities that utilize retrieval-augmented generation (RAG) functionality in their applications, even without an Internet connection.
Last but not least, Couchbase also launched Capella Free Tier, which gives customers access to pre-configured cluster templates ranging from one to five nodes. Capella Free Tier includes features like Capella iQ and Capella Workbench, and is designed to help interested users quickly kick the tires on Couchbase to see if it’s something they’d like to invest more time and money into.
You can read more about these announcements in the Couchbase blog.
Related Items:
Couchbase Bolsters GenAI Development with Vector Search, RAG
Couchbase Advances Case for Becoming Your System of Record
There’s a NoSQL Database for That
Source link
lol